Exploring the power of GNN + alpha in EDA
This project explores the power of graph neural network (GNN) and alpha (something else) in high-level synthesis and logic synthesis (what else?).
- GNN + RL: GNN-assisted design space exploration in high-level synthesis via reinforcement learning
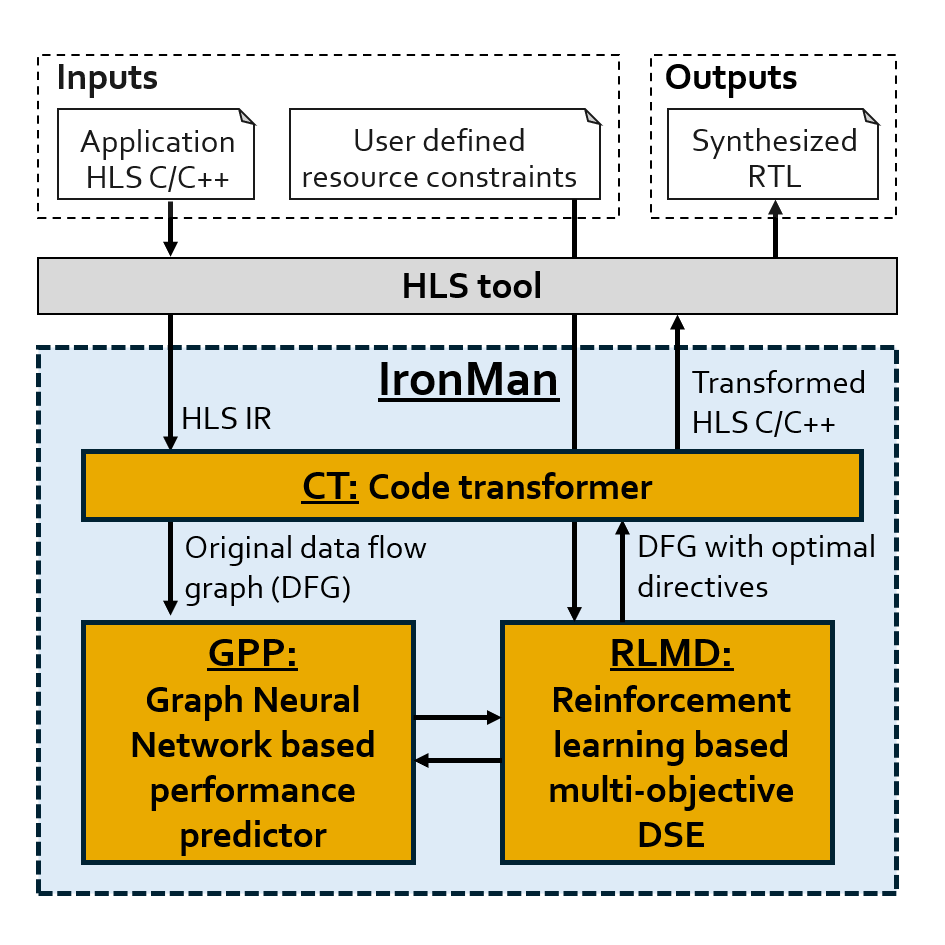
- [Paper] Some amazing results can be found in this paper – IronMan. It wins the best paper award in GLSVLSI’2021.
- GNN + Hierachicle: improvement on top of IronMan with more challenging tasks and smart innovations
- [Paper] HLS performance prediction using GNNs: benchmarking, modeling, and advancing @ DAC’22
- GNN + LSTM: logic synthesis optimization
- Lostin: Logic Optimization via Spatio-Temporal Information with Hybrid Graph Models @ ASAP’22

Domain-Specific Accelerators on FPGA — GNN and beyond
FPGAs are good platforms for domain-specific applications. We’re generally interested in accelerating “almost” everything on FPGA as long as it’s necessary: DNNs, GNNs (both training and inference), graph computations, etc. Especially we’re building GNN accelerators on FPGA, which is of great importance for scientific computing.
- Streaming-based GNN accelerators
- Graph algorithms
- MeloPPR: Personal Pagerank @ DAC’21
- [Ongoing] Let’s automate the GNN accelerator constructions!
- [Ongoing] What about dynamic GNNs?
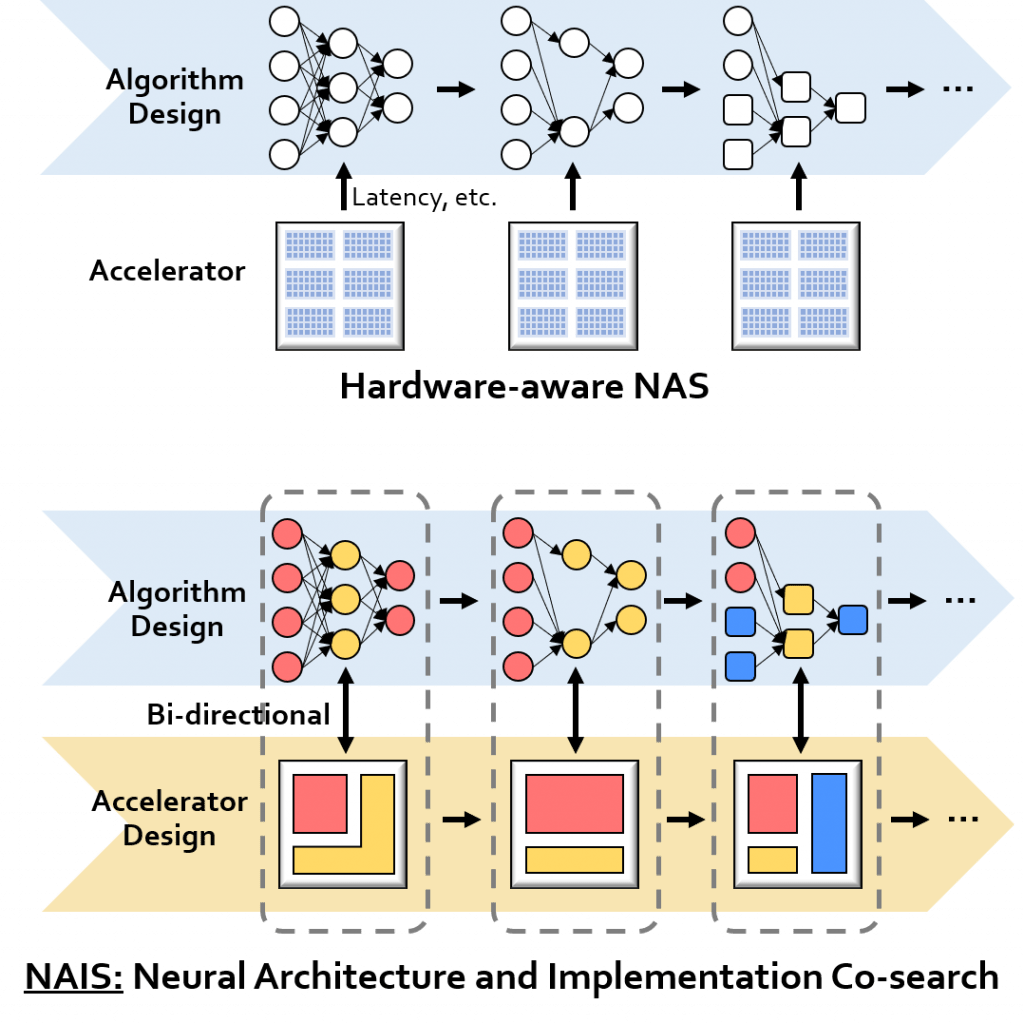
NAIS: Neural Architecture and Implementation Search
This project focuses on a novel co-search methodology beyond NAS (neural architecture search), called NAIS – neural architecture and implementation search. NAIS incorporates hardware implementation search into NAS to produce hardware-efficient AI algorithms as well as optimized hardware implementations, within limited hardware resource and performance constraints.
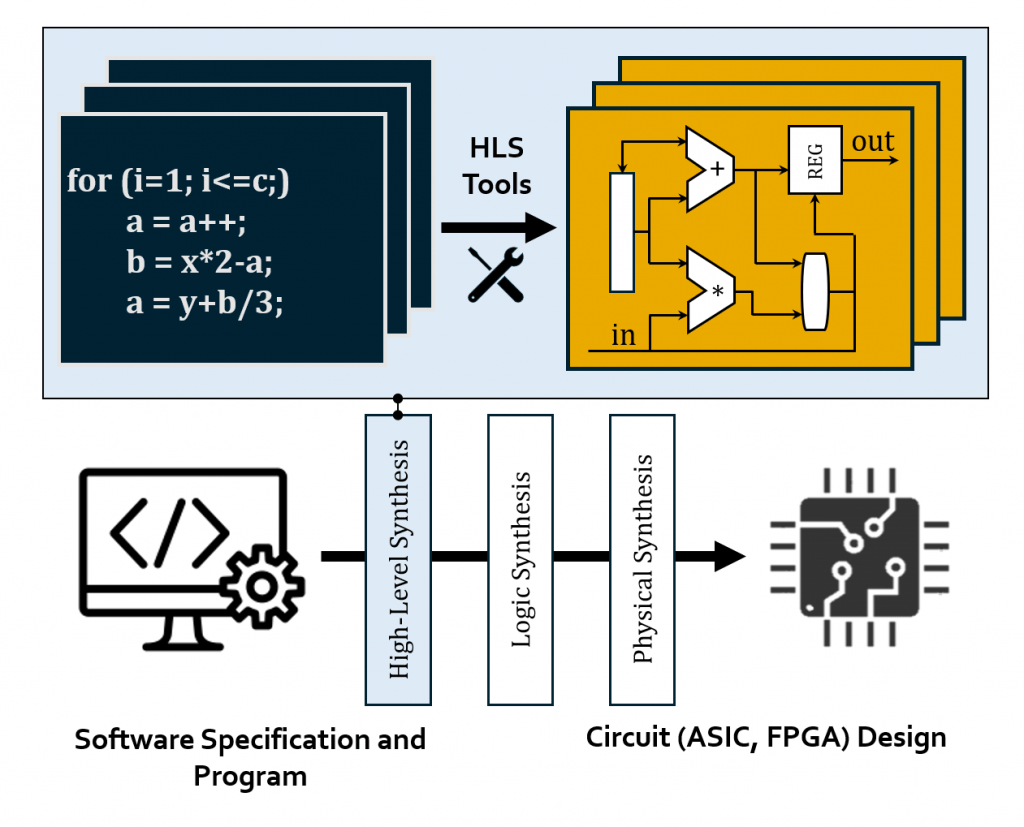
HLS: High-Level Synthesis for Agile EDA
High-Level Synthesis (HLS) is an automated design process that interprets an algorithmic description (C, C++, SystemC, etc.) of the desired behavior and creates digital hardware (VHDL, Verilog, etc.) that implements that behavior [ref]. HLS greatly boosts productivity for hardware development such as ASIC and FPGA design. Our main research interests include:
- [Past] Traditional HLS: core algorithms such as operation scheduling and functional unit and register binding.
- [Ongoing] Modern HLS: domain-specific (machine learning, graph processing) HLS, HLS for heterogeneous platforms, etc. HLS design space exploration: to further alleviate human efforts
- [Ongoing] We are exploring HLS for agile development and analog design automation. This is game-changing for analog/mixed-signal development!
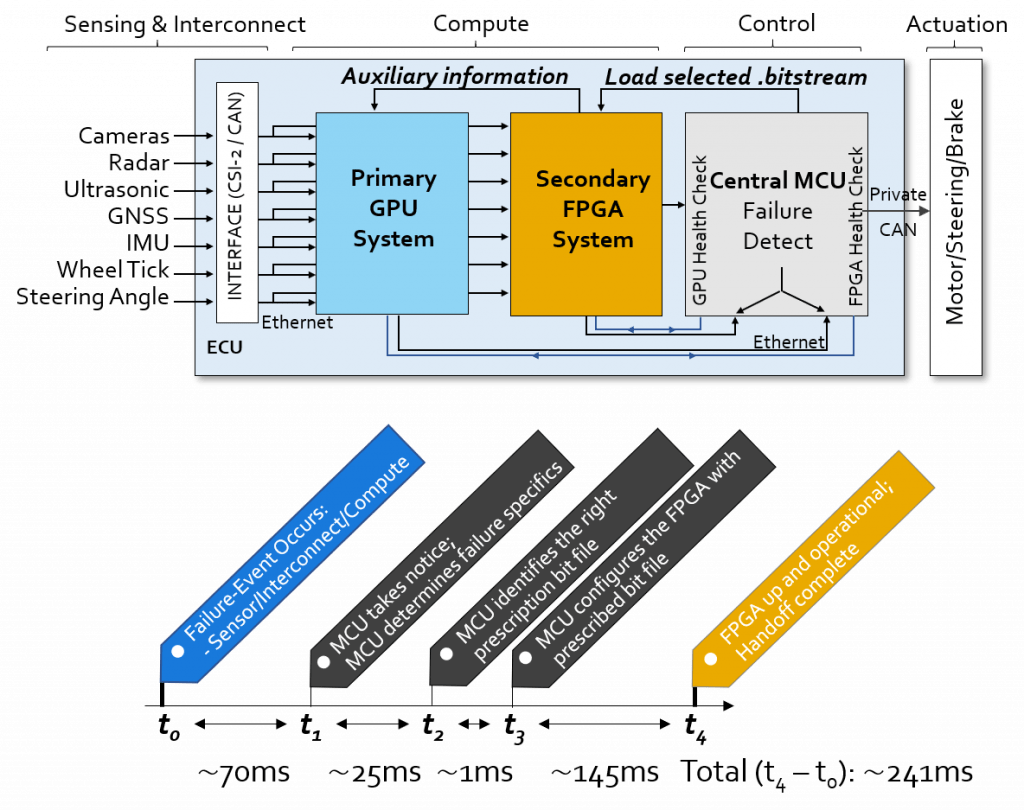
ML Algorithm and System for Autonomous Driving
We proposed a hybrid GPU + FPGA platform for autonomous driving cars, which introduces redundancy into the system for reliability: the FPGA system acts as a fallback system when GPU failure occurs. In addition, hardware heterogeneity decouples the development of the main driving task and safe-mode driving task, as well as the development of GPU and FPGA algorithms.
We’re also working on 2D/3D object detection for autonomous driving ith/without lidar sensors.